One of the things that I find a bit misunderstood in Power Query is whether or not Data Types matter. I mean, I’m sure everyone agrees to some point that they do, but you do know just how much they matter, and why?
Over the weekend, I received an email from one of our loyal students which read, in part:
I am going under the assumption that in Power BI nothing is free. Steps, calculated columns, measures and so on could be cheap but they are never free. It is with this premise in mind that I pose the following theory.
Users should sparingly use Change Type in Power Query. It is fine to Change Type when converting Date/Time to Date, Decimal Number to Whole Number, and others that actually change the value. It is a waste of resources to Change Type from Decimal or Whole Number to Currency. Even if you want the column to look like Currency, you can apply that format in the Data Model view and save one Power Query step.
On the face, this theory seems somewhat reasonable. After all, adding additional steps is bound to add some overhead to the Power Query process in most cases. And let’s be honest, in small models, it may make no difference to you at all. But when things get bigger…
Data Types vs Formats
To understand what Data Types matter, we need to get something very clear right off the bat: Data Types and Formats are not the same thing. Data Types dictate what kind of data you have and determine how much memory is allocated to store a value. Formatting, on the other hand, tell you how you want the values to appear. To see this in practice, have a look at the following values in Power Query, where the Data Type has been set to Currency:
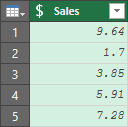
Notice that they only place you see a $ sign is in the header. And see how the decimal numbers do not line up? I can tell you from many years of teaching accountants, that this drives them bonkers. That 1.7 needs to be 1.70! But you don’t do this here, you do that in the Excel worksheet, Power Pivot model or Power BI visual.
They key to remember here:
- In Power Query, you define Data TYPES
- In Power Pivot, Excel or Power BI, you define Data FORMATTING
Excel’s Data Types
In the classic days of Excel, we only had four data types that we had to be worried about. Those were:
- Text,
- Numbers,
- Blanks, and
- Errors
(Although represented by textual patterns like #REF!, #N/A, #NAME?, and the like, they actually count as a different data type.) Today it gets a bit more complicated with Stock and Geography data types, as I blogged about here, but anything else was just a number that was formatted with a number formatting string. Examples of these include:
- Date: format it as a number, and you’ll see the number of days since Jan 1, 1900)
- Time: a little trickier, but this is just a fraction of a day where .25 is 6:00 AM, .5 is 12:00 PM and .75 is 6:00 PM. And if all you have is the time, and you format it as a DateTime, you get that time on Jan 1, 1900.
- True/False (Boolean): while this shows in the cell as TRUE/FALSE, which looks like text, if you multiply them by 1 you’ll see that TRUE equates to 1, where FALSE equates to 0.
But that was Excel, where data types and number formats where the same thing. That’s not Power Query.
Power Query’s Data Types
Unlike Excel, which has a pretty short list of data types, Power Query seemingly has a ton:
- Numeric Data Types:
- Decimal Number
- Currency (Fixed Decimal)
- Whole Number
- Percentage
- DateTime Data Types:
- Date/Time
- Date
- Time
- Date/Time/Zone
- Duration
- True/False (Boolean)
- Text
- Others (Binary, Tables, Records, Lists, and more)
- Any (the dangerous “undefined” type which allows the application to determine the correct data type)
The key to recognize, is that each of these data types is DISTINCT, meaning that each of these is different in some way from every other. (While we won’t get into it in this post, unlike Excel which implicitly converts data from one type to another, Power Query requires explicit type conversion via use of functions like Number.From() or Date.ToText(), which can be frustrating at times!)
For the purpose of this post, however, I want to focus on the first three numeric types: Decimal Number, Currency and Whole Number, and ask the question: Does the Data Type matter?
Illustration Background
Let’s have a look at an example. For the illustration, I set up a Power Query chain that looks like this:
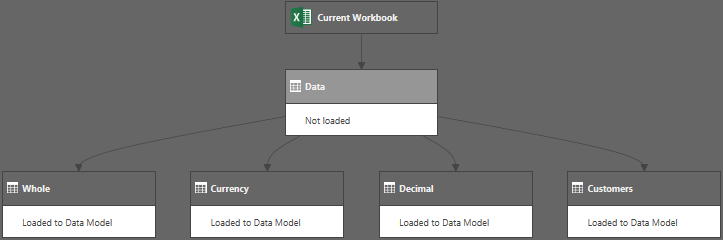
The Data table had 100,000 randomly generated [Sales] records that vary between 1.27317262341058 and 100000.017761279, and randomly generated [Customers] that vary between 1 and 1000.
The only change I made in the Whole, Currency and Decimal types was to set the Data Type for the [Sales] column accordingly. In the Customers table, I removed the [Sales] column and duplicates from the Customers column.
I then created 3 quick measures to sum the column up, and dropped them on a Pivot:
![]()
I don’t think it would surprise anyone here that the [Whole Sum] is slightly different than the [Currency Sum] and [Decimal Sum]. After all, the numbers were rounded at the source before being added up. And so far, we can see that the [Currency Sum] and [Decimal Sum] look pretty much the same. At least until we expand them a bit:
![]()
The only thing that should be a surprise here is that currency only holds up to four decimals, not two as most people expect. This actually makes sense when you start thinking about foreign exchange transactions, and how they are always carried to four decimal places.
But is that it? Is a Data Type just about rounding? As it turns out the answer to that is both yes and no.
Testing the Model Memory
The next step here was to test the model memory and see how Power Pivot is storing the data. To that end, here’s a little table that shows exactly that:
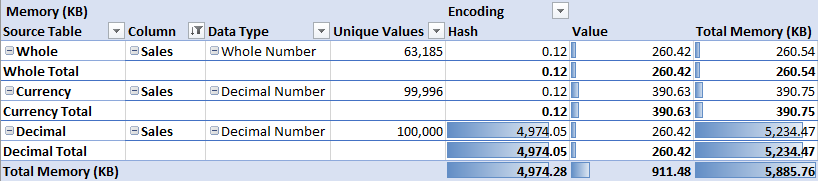
Before we get into this, I want to call out something important here. The Data Type that is showing has been read from Power Pivot. Notice that Whole Number shows as such, consistent with Power Query. But the Currency and Decimal tables both show Decimal. As it turns out, Power Pivot doesn’t make a distinction between these two data types. However, the distinction between these two Data Types matters to you anyway, as I’ll explain.
So, what does that all mean?
In the Whole Number table, I had rounded off all the decimals. This left 63,815 unique values. And because Power Pivot compresses based on unique values, it deals with this column very well, resulting in a total of 260.54 KB to store these values.
In the Currency table, I effectively rounded all the values off to four decimal places. This left 99,996 unique values in the table (only 4 values were repeats). Despite this, Power Pivot did a good job of compressing the values in memory, resulting in 390.75 KB to store them.
Then we get to the Decimal column. There are only 4 more unique values than in the Currency column, but the memory takes a colossal 5,234.47 KB to store the values, vs the 390.75 KB of Currency. What the heck is going on?
The answer lies in the fact that Power Pivot has to carry all of those decimal places, and once it does, it can flip to storing data using Hash Encoded memory. That’s a deep topic for another time but suffice it to say that this is a bad thing, as Value encoding is much more efficient. (Hash is generally used for Text, and Values for… you guessed it… values!)
Interestingly, if you round the Decimal Number to 5 decimals you end up with 99,999 unique values in the column and a very minor change to the memory used. But if you round it to 4 decimals, the memory of the Decimals column compresses the same as Currency, and the memory need drops to the same 390.75 KB.
Why Model Memory Matters
And this is the final part of the equation to me. Not all time is created equal. My users will accept a 2-minute refresh of the data model. They might say it takes time, but +/-30 seconds in a refresh isn’t anything that they’ll get overly concerned with. They’ll click Refresh, go grab a coffee, then come back to work with the file.
But if they click a slicer and it takes 10 seconds to redraw the Pivot Table or Power BI visuals? Watch out! They’ll claim the model is too slow, ineffective, wrong and useless. I’d MUCH rather push resource consumption into the initial refresh in order to build a memory-efficient model that performs well when being used for analysis.
Wait, what happened to the Data Types?
To be fair, Power Pivot’s compression mechanism is more about unique values and the length of precision than it is about Data Types. But it’s up to you to choose the correct Data Type to future-proof your model and make sure that the compression algorithms can be applied.
But due to the way Excel has always worked, the way the Data Types are named, and the fact that most modellers don’t have a clear understanding of Formatting vs Data Types… users are more likely to pick Decimal over Currency. I mean, why would I ever format my units as Currency? (In Power BI this is called a Fixed Decimal, although it still shows with the currency symbol.)
We need to recognize that lagging decimals really do happen in business. Let’s look at that Units column for a second. Naturally we never sell a partial unit… or do we? I’ll give you 3 examples of things I’ve seen in the Food and Beverage industry that forever changed my opinion on this:
- We had a couple of customers who insisted that they be able to purchase half a muffin. I’m not even kidding here. The killer for me was that it only showed up every 10,000 rows of transactions or so, meaning that the column often got set to Whole Number incorrectly.
- The salesperson agrees to provide those 300 units for $5,000. No big deal except that they monkey the price field in your database to make it work and you suddenly you have a sales price of $16.666667. Fortunately, this one usually gets rounded via setting it to a Currency Data Type, as that’s logical. But what if you set it to decimal or left it undefined?
- Things go the other way and the customer agrees to a package price of $5,000 for something that usually carries a price of 17.00 per unit. It gets rung into the system with a reverse engineered quantity of 294.1176470588235 to get it exactly right.
The last is the real kicker as the memory suddenly flips from Value to Hash, the RAM needed to refresh the data expands exponentially and brings your model to its knees. And now every slicer click has gone from 1 second to update your visuals to the better part of 10 seconds. And your audience is screaming that the model is “unusable”.
My Recommended Practice
The final step in every query I build which loads to a destination (an Excel Table or the Data Model) is to correctly define my Data Types. This does two things for me:
- It ensures that I never accidentally load a column with an undefined Data Type. (In the case of Dates, they load to Excel as numbers, and to the Data Model as text!)
- It ensures that I’m cutting down to the minimum number of decimals I’ll ever need for my analysis.
Does it take more processing time? Maybe marginally. But does it future-proof my solution to keep it performant? Definitely. And it ensures the time to do so happens in the refresh, not in when the model is being used for analysis.
Some Final Thoughts
The issues you saw here with memory also affect DateTimes in a big way, as they are quite similar to decimal numbers, where time is represented as the fraction of a day.
The article touches on some things from a much bigger topic: how to optimize a Power Pivot/Power BI data model. I actually teach a full day course on this topic for CPABC, where we cover how the Vertipaq engine compresses its data, why you want to avoid calculated columns and fall in love with measures. We make extensive use of Power Query in this course to reshape tables (applying correct data types along the way) so that they can be consumed by the data model in a more efficient manger. We dissect a poorly built model, test its memory and then rebuild it in stages seeing how our changes made an impact.
And if you’re looking for tools to help with this process… stay tuned to this blog. I’m hoping to have an announcement on that front within the next couple of months.
12 thoughts on “Do Data Types Matter in Power Query?”
Interesting article to speed Power Query with the correct Data Types.
Despite the fact that you can do arithmetic with it, "Logical" should probably be considered a separate data type in Excel; the "TYPE" formula returns a specific value (4) for it.
Pingback: Power BI Paginated URL Parameters are here! (Roundup | September 2, 2019) | Guy in a Cube
Pingback: Power BI Paginated URL Parameters are here! (Roundup | September 2, 2019) - Learn Power BI
Fair enough Curt, I can accept that! 🙂
Hi Ken,
I current practice is the same as yours (probably from reading your blog) that I only change the datatypes at the end of a power query as the data is transitioning to Excel or PowerPivot. I leave most fields as Any so errors will get detected early, and I don't need to edit my queries when new unexpected columns are added to the input data, but not used in the query.
But what I am wondering about, and I had thought you were going to cover in this article, is whether datatypes affect powerquery performance or memory consumption.
I have a powerquery model for a client that is close to unmanageable due to it taking 45 mins to process and I am wondering if I converted to currency early in the processing, whether it would make a difference.
Any insight into PowerQuery and Datatypes??
Thanks - love your blog
Hi Charles,
Honestly, I think the answer is going to be "it depends". But my suspicion is that if you have a query that the data types are the least of the issues. It's much more likely that something else is killing the performance.
Hi Ken,
In Power Query, I have a column that is a decimal type by default. The values are whole numbers up to 11 digits (represents ID). Is it better to change data type to TEXT or WHOLE NUMBER? Or should I just leave it as DECIMAL. Once in Power BI Desktop, I would be splitting this to rightmost 9 digits and the remaining digits to the left if any. I'm even thinking of just splitting the column in Power Query so that each of the 2 columns will have less number of unique values. Any best practice tips?
Best regards,
Ferdinand
If they are whole numbers, make them whole numbers as that is the most efficient data type. Text is the least, so definitely don't go there.
Hello Ken, I need to preper a little presentation on the topic of data types in Power Query. Your blog is a fantastic help here. One thing I do not understand though, is the data type BLANKS in Excel. Does that mean, that for each unused cell in a worksheet, that cell is saved as BLANKS?
Would highly appreciate your thoughts on this.
Thank you, Giuseppe
Hi Giuseppe,
In Excel, blanks are more like "empty", or "non-data". Excel doesn't take any space to store them. In Power Query, blanks get represented as "null", which is essentially and empty data point as well.
So arguably it's not really a data type, as much as the lack of a data type (which to me counts as a data type of it's own.)
Hi Ken,
Finally with your excellent article, you've solve a big question for me and I will be more confident using Data types.
Thanks a lot!
Carlos